在當今大數據與高并發(fā)應用蓬勃發(fā)展的時代,傳統(tǒng)的集中式數據存儲方案已難以滿足海量數據、高可用性及彈性擴展的需求。分布式數據存儲作為現代架構的核心技術之一,不僅解決了數據容量與性能的瓶頸,更構建了數據處理與存儲的強大支撐服務體系。本講將深入探討分布式數據存儲的核心原理、關鍵技術及其如何作為服務,支撐上層應用的數據處理需求。
一、分布式數據存儲的基本概念與價值
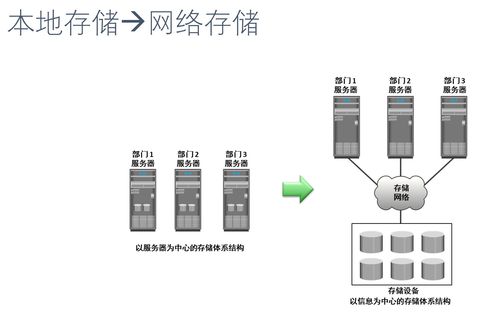
分布式數據存儲是指將數據分散存儲在多個獨立的節(jié)點(服務器)上,這些節(jié)點通過網絡互聯,對外提供一個統(tǒng)一的邏輯視圖。其核心價值在于:
- 可擴展性(Scalability):可通過水平添加節(jié)點來近乎線性地提升存儲容量與處理能力。
- 高可用性與容錯性(High Availability & Fault Tolerance):數據多副本存儲,單個或多個節(jié)點故障不影響整體服務。
- 高性能(Performance):數據分布存儲,讀寫負載可分散到多個節(jié)點并行處理,降低單點壓力。
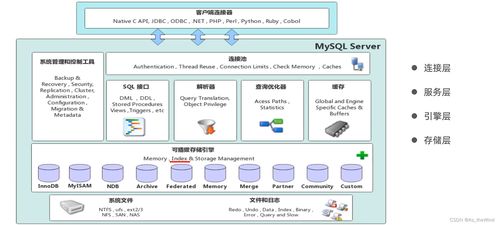
二、核心數據處理與存儲支撐服務
分布式數據存儲并非孤立的存儲層,它通過一系列關鍵服務,為上層的應用、分析與計算提供堅實基礎。
- 分布式文件系統(tǒng):
- 角色:提供跨多個存儲節(jié)點的統(tǒng)一文件命名空間,管理超大文件的塊劃分與分布。
- 代表技術:HDFS(Hadoop Distributed File System)、GFS(Google File System)。
- 支撐服務:為批處理框架(如MapReduce、Spark)和海量日志存儲提供底層存儲支持,是大數據生態(tài)的基石。
- 分布式數據庫與NoSQL:
- 角色:提供結構化或半結構化數據的存儲與訪問,通常犧牲部分ACID特性以換取擴展性與性能。
- 分類與服務:
- 鍵值存儲(Key-Value Store):如Redis、DynamoDB,支撐高速緩存、會話存儲和簡單查詢場景。
- 文檔數據庫(Document Database):如MongoDB、Couchbase,支撐靈活 schema 的內容管理、用戶檔案存儲。
- 列式數據庫(Wide-Column Store):如Cassandra、HBase,支撐海量數據的隨機實時讀寫,適合時序數據、監(jiān)控數據。
- 圖數據庫(Graph Database):如Neo4j,高效支撐社交關系、推薦系統(tǒng)等復雜關聯查詢。
- 分布式協調與元數據服務:
- 角色:維護集群狀態(tài)、配置信息、節(jié)點發(fā)現與領導選舉,是分布式系統(tǒng)的“神經系統(tǒng)”。
- 代表技術:ZooKeeper、etcd。
- 支撐服務:為分布式數據庫、微服務架構提供強一致的配置管理、分布式鎖和命名服務,保障系統(tǒng)協調一致運行。
- 分布式緩存服務:
- 角色:將熱點數據存儲在內存中,極大降低后端數據庫壓力,提升應用響應速度。
- 代表技術:Redis(分布式模式)、Memcached。
- 支撐服務:支撐高并發(fā)讀場景,如網頁緩存、商品信息查詢、秒殺系統(tǒng)。
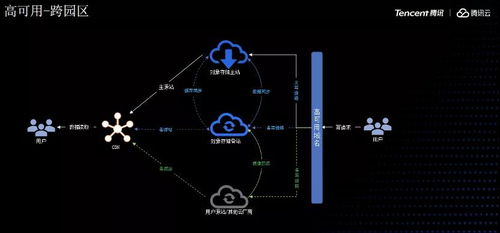
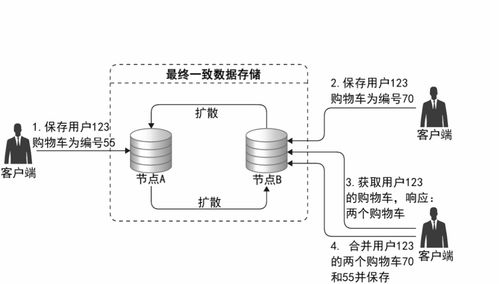
- 數據復制與一致性服務:
- 角色:在多個節(jié)點間同步數據副本,并在一致性、可用性和分區(qū)容錯性之間取得平衡(CAP定理)。
- 支撐服務:通過主從復制、多主復制、分片(Sharding)等策略,保障數據可靠性與服務連續(xù)性,是構建高可用存儲服務的核心。
三、技術挑戰(zhàn)與設計考量
在利用這些支撐服務時,架構師必須權衡以下挑戰(zhàn):
- 數據一致性模型:根據業(yè)務需求選擇強一致性、最終一致性還是會話一致性。
- 分片策略:如何設計分片鍵(Shard Key)以實現數據均勻分布并避免熱點。
- 故障恢復與數據再平衡:節(jié)點增刪或故障時,如何自動遷移數據并恢復服務。
- 跨數據中心部署:如何實現異地多活,滿足容災與低延遲訪問需求。
四、
分布式數據存儲技術已演化為一套多層次、多形態(tài)的數據處理與存儲支撐服務體系。從底層的文件存儲,到在線的數據庫與緩存,再到保障一致性的協調服務,它們共同構成了云時代和互聯網規(guī)模化應用的數字基座。理解和掌握這些核心技術服務,并能夠根據具體的業(yè)務場景(如數據量、讀寫模式、一致性要求)進行合理選型與架構設計,是每一位后端與系統(tǒng)架構師的必備能力。未來的趨勢將朝著更智能的自動化管理、更統(tǒng)一的多模數據處理以及云原生深度集成等方向持續(xù)演進。