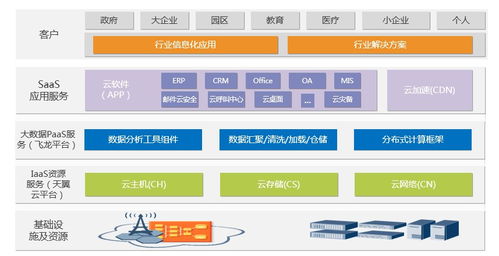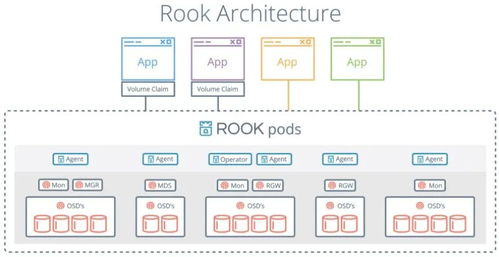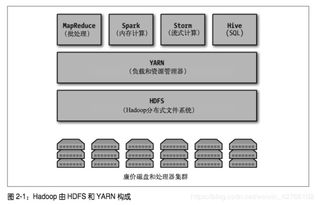
在《Hadoop數據分析》的第二章中,作者深入探討了作為大數據核心基礎設施的“大數據操作系統”概念,并著重分析了其數據處理和存儲支持服務。本章內容揭示了Hadoop生態系統如何扮演類似傳統操作系統的角色,為上層應用提供基礎資源管理和服務支撐,而數據處理與存儲正是其兩大基石。
一、 數據處理支持服務:批處理與交互式查詢的引擎
數據處理是大數據價值實現的關鍵環節。Hadoop生態系統提供了多樣化的處理框架以滿足不同場景的需求:
- 批處理引擎(MapReduce):作為Hadoop最初的編程模型,MapReduce通過“分而治之”的思想,將大規模數據集的處理任務分解為Map(映射)和Reduce(歸約)兩個階段。它擅長處理海量歷史數據的離線分析,其高容錯性和可擴展性是其核心優勢。其多階段磁盤I/O的特性也導致了較高的延遲。
- 交互式查詢引擎(Hive, Impala):為了滿足更快的即席查詢需求,以Hive(基于MapReduce或Tez/Spark)和Impala(MPP架構)為代表的SQL-on-Hadoop工具應運而生。它們允許用戶使用熟悉的SQL語言對存儲在HDFS或HBase中的數據進行查詢和分析,極大地降低了大數據分析的技術門檻,提高了開發效率。
- 流處理引擎(Spark Streaming, Flink, Storm):對于需要實時或近實時處理無界數據流的場景(如日志監控、實時推薦),Spark的微批處理、Flink的純流處理以及Storm等框架提供了強大的支持,實現了從“存儲后分析”到“運動中分析”的范式轉變。
二、 存儲支持服務:分層化與多元化的數據湖倉
可靠、可擴展且經濟的存儲是數據處理的前提。Hadoop的存儲體系已從單一的HDFS演變為一個層次分明、功能互補的生態系統:
- 分布式文件系統(HDFS):作為基石,HDFS以“一次寫入、多次讀取”的模式,將超大文件分塊存儲在廉價的商用服務器集群上,提供了極高的吞吐量和容錯能力。它是原始數據、清洗后數據以及需要批量處理數據的主要歸宿。
- NoSQL數據庫(HBase):建立在HDFS之上的HBase是一個分布式、列式存儲的NoSQL數據庫。它支持海量數據的隨機、實時讀寫訪問,非常適合作為需要低延遲查詢的在線應用(如用戶畫像查詢、消息歷史記錄)的存儲后端,彌補了HDFS在隨機訪問能力上的不足。
- 數據倉庫與數據湖(Hive, Kudu):Hive的表結構(Metadata)管理能力,使其在HDFS之上構建了一個邏輯數據倉庫。而像Kudu這樣的存儲引擎,則試圖融合HDFS的吞吐量和HBase的隨機訪問性能,為需要同時支持快速分析查詢和實時更新的場景提供了新的選擇。
三、 協同工作與核心思想
數據處理與存儲服務并非孤立運行。一個典型的數據管道可能是:原始日志實時攝入Kafka,由Spark Streaming進行初步處理和清洗后,將結果寫入HDFS作為長期歸檔,同時將聚合后的關鍵指標寫入HBase供儀表盤實時展示;而周期性的深度分析任務則由Hive或Spark SQL在HDFS的數據上運行。
本章的核心思想在于闡明,一個成熟的大數據操作系統(以Hadoop生態為代表)通過提供多元化的處理范式和分層化的存儲方案,使企業能夠根據數據的特性(體量、速度、多樣性)和價值密度,靈活地選擇性價比最優的技術組合,從而構建起一個統一、彈性、高效的數據平臺。這為實現從數據到洞察、再到決策的完整價值鏈奠定了堅實的技術基礎。
思考與啟示:隨著云原生和存算分離架構的興起,大數據操作系統的內涵正在不斷擴展。但無論如何演變,其對數據處理與存儲基礎服務的抽象、管理與優化,始終是支撐一切上層智能應用的根本。